This tutorial from Bhusan Chettri is focussed on providing an in-depth understanding of IML from multiple standpoint taking into consideration different usages (use-cases), different application domains and emphasising why it is important to understand how a machine learning model demonstrating impressive results make their decisions. The tutorial also discusses if such impressive results are trustworthy to be adopted by humans for use in various safety-critical businesses for example: medicine, finance and security. Dr Bhusan Chettri who earned his PhD from Queen Mary University of London aims at providing an overview of Machine Learning and AI interpretability.
Now, before diving into the topic of IML or explainable AI (XAI), it is worth revisiting some of the vital concepts revolving around data, Machine Learning, AI and how these systems function. With a good grasp of such concepts it becomes easier for readers from non-technical or non CS background to gain a better insight about the underlying phenomenon related to model interpretability. For technical readers (CS or AI background) these may be too basic.
Data and Big data
Data is the driving fuel behind the success of every data-driven AI and Machine Learning (ML) based application. Do you agree? Okay, so what is data? Anything that exists in nature; represents some facts or figures is regarded as data. An image of a dog; numbers between 1 to 10 are all examples of data. Data is often available in raw format and they need to be corrected before using them in a Data Science or ML pipeline. For example, errors can occur during data collection and processing such as labelling of a data sample to a certain class (image of a Cat being labelled as Dog or an image of a Horse labelled as Cat) or recording errors made by an automatic device (reading taken from a faulty thermometer under different weather conditions). Furthermore, in the current era of “Big Data” where data is produced and collected on a massive scale world-wide, there is an enormous amount of data available digitally online. To summarise, some of the sources of data are: retail and wholesale transactions; data collected from the use of various sensors; data collected through video surveillance; population census data; social media such as Facebook, Twitter, YouTube and blogging etc. A post published in 2018 at forbes.com (here) regarding how much data is produced on the internet through various mediums (like social media platforms, online transactions etc) revealed interesting or rather shocking reports. For instance, as per their analysis, in just a minute time interval snapchat users were found to share 527,760 photos, instagram users were found to post around 46,740 photos. If these numbers of image data are uploaded in a single minute, then just imagine how many photos are produced/uploaded in a single day, a month, and a year time?
Although there is a massive amount of digital data available, they are not in a structured form and therefore hinders using them directly in a downstream AI pipeline. But, what does it mean by structured and unstructured data? Data prepared and arranged in some particular format, for example multidimensional arrays; tabular or spreadsheet-like data where each column holds values of different types (numeric, string etc), CSV (comma separated value) files are all examples of structured data. On the contrary, contents of web pages, documents, multimedia data etc are unstructured as they need some form of processing and cannot be used directly. Even though it may not always be obvious, a large percentage of such data can be transformed into a format that is more suitable for analysis and modelling. For instance, a collection of news articles could be processed into a word frequency table which could then be used to perform sentiment analysis. Big Data, therefore, is often not immediately useful. It needs to be examined, aggregated, to make sense of the endless stream of bytes. Thus engineers/researchers often spend a considerable amount of time performing initial data exploration (data cleansing, aggregation etc) before being able to use them in an AI/ML pipeline.
Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning
AI can be defined as a general field which involves rules, logic and data (to some extent) and has evolved over time encompassing both ML and deep learning as its sub-fields. Bhusan Chettri explained in other words a simple computer program consisting of several if-else decision making rules can be regarded as an AI where there is no data-driven learning involved. It consists of a large set of rules transforming inputs to a corresponding decision (or the output). A classic example of this is chess programs in early days (before deep learning kicked off) which had only a set of hard-coded rules defined by a designer or programmer and this does not qualify as machine learning as there is no learning involved. However, ML and deep learning are completely data-driven learning and make massive use of data. They do not use hand-crafted rules to define an answer or outcome to a problem being aimed to solve. During the period between 1950 – 1980, which was often called as an era of symbolic AI there was a belief among researchers/scientists that human-level AI was achievable by making use of a large set of explicit carefully handcrafted rules for manipulating and representing knowledge base. Interestingly, the symbolic AI methodology worked quite well for tasks such as playing chess – which were of course very simple but these approaches failed dramatically for other complex problems such as speech recognition, image classification, language translation, language recognition etc. Thus, this aspect led to the invention or rise of what we call Machine Learning – a fully data driven mechanism that aims at learning patterns within the data to discover correlation between the data and the answer (or label of data).
In traditional AI (also called symbolic AI) which is based on classical programming the input rules (set of instructions to a computer) and data is provided as input to such a system. These predefined rules are applied on the data to produce answers. On the contrary, users provide both data and expected outcome/answers from data to produce the rules as output. A Machine Learning system does this by exploiting patterns within the data and associated class/answers. Then these rules can be then applied to new data to produce answers. A Machine learning system is trained unlike symbolic AI which is explicitly programmed. It is presented with many examples relevant to the task, and it finds statistical structure in these examples that eventually allows the system to come up with rules for automating the task. For example, in order to build a voice authentication system using machine learning, a lot of speech samples spoken from multiple speakers are collected to train the system. The system is trained to learn a pattern that differentiates one speaker from another while making less errors in detecting true speakers.
Deep learning is a subfield of Machine Learning which is also data-driven but makes use of neural networks in solving a problem. In simple words, deep learning refers to a neural network with more than one hidden layer for learning representations. The learning process primarily aims to mimic human brains in performing various tasks through a series of non-linear transformations of input data to achieve the desired output. Usually, the first layer of the neural network is called the input layer that encodes the input data and the last layer of the network is referred to as the output layer which comprises a set of units (or neurons) representing the desired outputs. The remaining layers in the network are often referred to as hidden layers. As humans or programmers do not have direct control on these layers, deep neural network models are often called as black box models. For example, consider the design of an automatic gender classification system using deep neural networks. The input layer will have N (this will depend upon the size of actual input features used by the programmer) number of neurons that will take various attributes of person’s as input. These attributes might include voice pitch (also called fundamental frequency), body weight, height etc. Here, the output layer will have two neurons (or output units) where one neuron denotes Male class and the other Female class. The network can have M number of hidden layers (which again depends upon the programmer/engineer/researcher’s design choice) which will take the input data and apply a series of non-linear transformations in order to learn the mapping function from input to output.
During the network training the algorithm responsible for providing such capability to learn in an iterative fashion is called back-propagation. Infact, back-propagation is actually the driving engine of every neural network that undergoes a continual learning process by adjusting the parameters often called weights of the neural network. In layman terms these weights can be thought of as a bunch of numbers organised in a table or matrix form where every number has a special purpose or meaning. There will be one such matrix learned for each of the hidden layers of the network so that the learned transformation function is correctly mapping every input to its correct class.
There are two terms associated with the use of artificial neural networks: shallow learning and deep learning. So what is the difference between the two? Shallow learning simply refers to the use of artificial neural networks with a single hidden layer. On the contrary, deep learning basically refers to the use of more than one hidden layer in learning the transformation function towards solving a given problem. The ability to perform large matrix multiplication between input data and the weight matrices during the learning process (training phase) has been possible today because of high-end computing infrastructure and advancement in algorithms. Thus deep learning is more popular in comparison to shallow learning nowadays.
Interpretable Machine Learning (IML) a.k.a Explainable AI (XAI)
Interpretable machine learning, often referred to as explainable AI (XAI), is a field of machine learning aimed at understanding how a model makes a decision of an outcome. Is the model exploiting cues from the underlying data that is relevant to the problem? What parts of input are more contributing towards a prediction? These are some of the questions that IML or XAI aim to address. And, there has been significant demand and interest in research on interpretability in recent years by academics and tech companies such as Meta, Google, IBM, Microsoft and more around the globe.
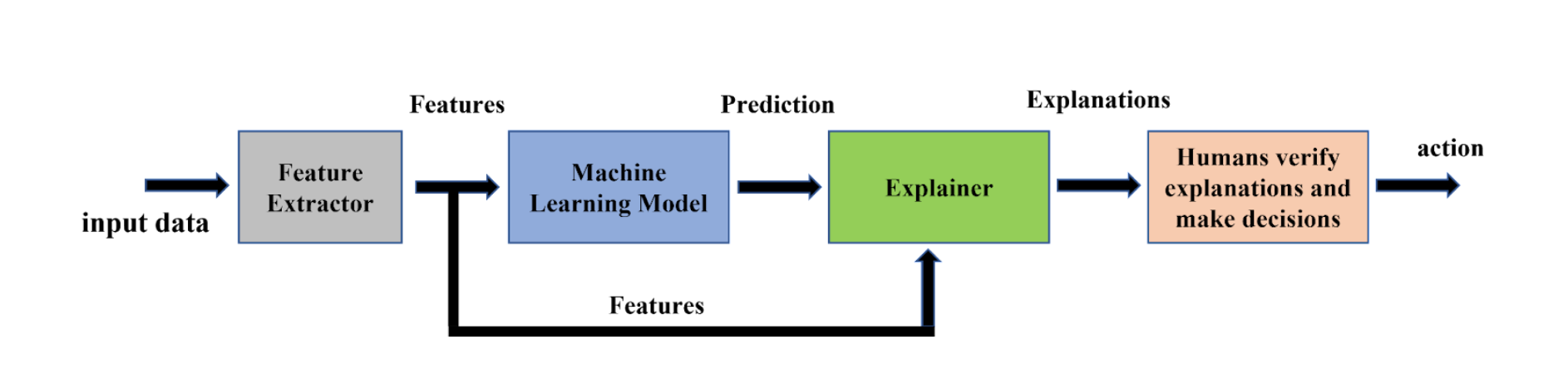
Fig 1: A basic overview of an Interpretable Machine Learning framework where humans verify the explanations to make final decisions by Bhusan Chettri.
Figure 1 by Bhusan Chettri illustrates an interpretable machine learning (IML) framework. The framework showcases an ideal scenario where a human is involved inorder to verify the explanations provided by an explainer a.k.a IML algorithm. Here the IML algorithm shown is a post-hoc interpretability method which operates on pre-trained ML models. This means that once a ML model has been trained, an IML algorithm can be applied on it. For this, the framework takes both the feature extractor and the ML model ensuring that features are extracted in a similar way as done during training and then prediction is obtained for an input test example. This process is illustrated in the figure. The output from an explainer is an explanation which could be, for example, a list of words highlighting the significance of various words in a given input sentence that was highly contributing towards that particular prediction.
The rise of Artificial Intelligence which can be attributed to the successful use of deep learning algorithms, in particular, has brought a revolution in almost every domain and business showing impressive results. The two main factors contributing to this success are: (1) Big data and, (2) Computational resources. As explained earlier in the post, every business is now able to collect a vast amount of data through digitization of their business process, which is used in training their AI systems. Furthermore, with the advancement in Computational hardware, for example, availability of Graphical Processing Units (GPUs) have enabled high-demanding mathematical computations much faster thus allowing researchers to run experiments on large datasets.
However, several safety-critical applications cannot simply use them without understanding how it forms decisions under the hood. For example, domains such as finance, medicine/healthcare and security (to name a few) require sufficient explanations to ensure fairness, reliability and trustworthiness of decisions they make. These models are black boxes. All that is known about them is that it takes certain input data and produces the output. Bhusan further say’s Yes, in many applications explanations may not be that important and all that matters would be just numbers – good results or say accuracy. Such businesses don’t care how their model arrived at such a decision because the result is pretty good and most importantly their client is happy. So all sorted.
However, this is not true with every domain as discussed earlier. There is a danger in using such black boxes without understanding their working mechanism. Also, research has shown that deep learning models can be fooled very easily by just making a tiny perturbation to its input data (which to humans is undetectable), yet the machine learning system produces completely different results. This is very dangerous. This means that an attacker can easily manipulate the input data passed to a neural network to produce the output they desire. Chettri gives an example, imagine a scenario where a Text-to-Speech system takes the input text “I will call you tonight” but the system gets manipulated by an attacker to produce the speech that sounds “I will kill you tonight”. This field, not within the scope of today’s discussion however, is called Adversarial Machine Learning, a very hot topic in the field of AI that is actively being studied by researchers around the globe.
Machine learning and deep learning models are heavily data-driven. This means that they learn to perform task discovering/learning patterns within the training data fed to the learning algorithm. Thus, the quality of data is one important factor that needs to be considered before using them in building ML models. The training data must be balanced across different classes of interest. For example, while building a gender classification system if the training data across two classes is imbalanced then there is a high probability that the model will pickup this imbalance factor and favour the gender class having more training samples (which is quite obvious). Bhusan Chettri gives another example to illustrate such imbalance data bias could be training an image classifier to recognize ten different classes of animals using pre-captured images with following data distribution per class: 80% of training samples contain images of Cat; 5% samples are of Horses; and remaining 15% constitutes other 8 classes. What do you think would such a model learn? Do you think such a model would perform fairly in real-world applications if deployed? The answer is No. This model no doubt may show 100% detection accuracy for Cat images but shall perform miserably for other categories of images. Due to an imbalance in training data across different classes, the model in question is heavily biased to detect one class while showing poor performance in other classes. This model is not trustworthy to be deployed in the real world. Likewise, training data must not have any other kind of biases resulting from initial data collection and post processing (it often happens while using automatic pipelines for data collection). Thus data used must be free of biases to ensure that the final model is reliable and unbiased. Drop your questions.