Voice biometrics in simple words refers to the technology used to automatically recognise a person using their voice sample. Every person possesses a unique vocal apparatus and therefore the characteristics and features of an individual’s voice is distinct. This is one of the key reasons for wide adoption of voice as a means of person authentication across the globe. In this article, Dr Bhusan Chettri explains the basics of voice biometrics and briefs about growing concern regarding its security against fake voices generated using computers and AI technology.
Voice biometrics are commonly referred to as automatic speaker verification (ASV). Two key steps are required to be followed in order to build such a system using a computer.
Training phase
It involves building a universal voice template a.k.a speaker template (or model) using large amounts of voice samples collected from different people with different cultural background, ethnicity and from different regions across the world. The more data recorded/collected under different diverse environmental conditions from a large speaker population the better will be the universal template because with such diverse data the template will be able to capture and represent the general voice pattern of speakers across the world. Furthermore, the voice template (also referred as speaker model) is simply a large table (or matrix) of numbers learned during the training such that each number in the table represents some meaningful information (about the speaker) which the computer understands but is hard for humans to interpret. As illustrated in Figure 1, top row, this step is often called offline phase training.
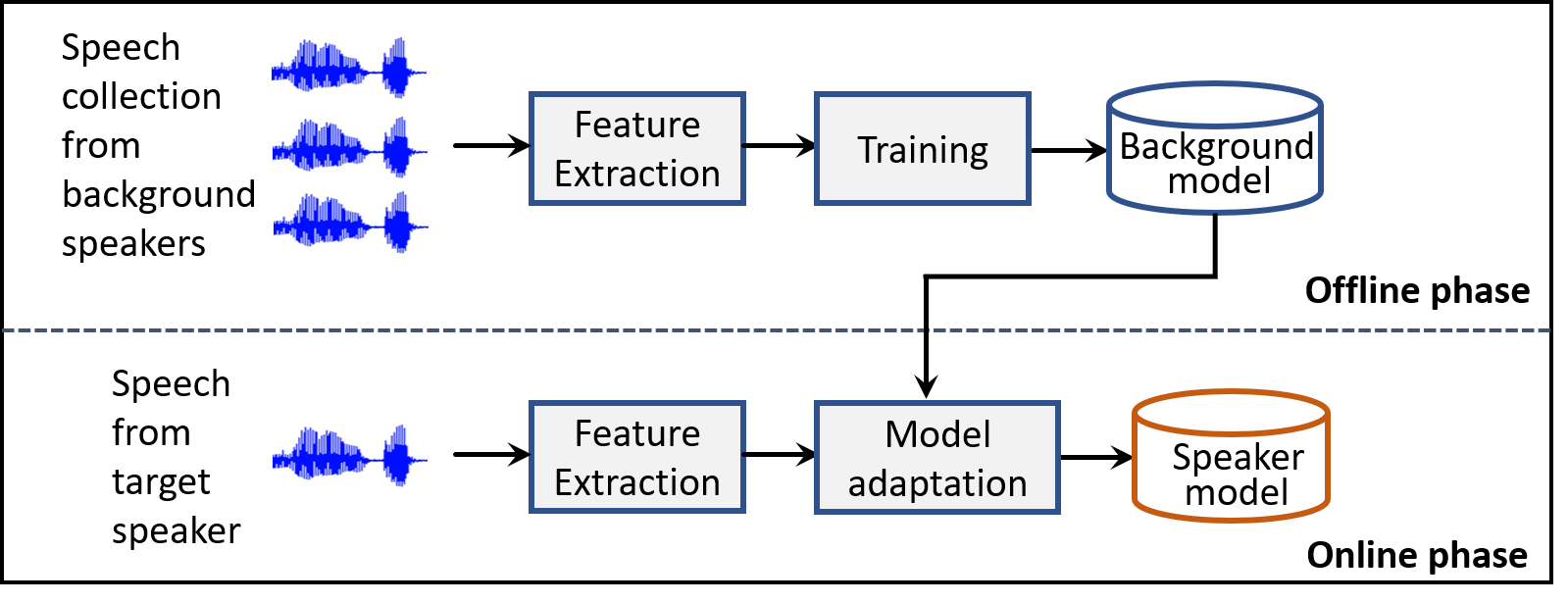
Figure 1. Training phase. The goal here is to build speaker specific models by adapting a background model which is trained on a large speech database.
Here, the feature extraction step simply gathers relevant information from the voice/speech samples of speakers and use them for building the voice template. The training step then makes use of the features being extracted from voices and applies computer algorithm to learn patterns across different voices. As a results this step produces the so called background model which is nothing but the universal speaker template representing the whole speaker/voice population. Then the next key step in training phase is building speaker specific model or voice template for a designated speaker making use of the universal speaker template. One interesting point to note here is that this step, also called speaker or voice registration, does not require huge amount of voice samples from the specific target speaker. And, it is also impractical to collect thousands of hours of speech/voice samples for one speaker. This is the reason why universal speaker/voice template are created and are then adapted to build speaker specific template. What this means is that using a small fragment of voice samples (usually 5-10 seconds or a minute speech sample) the large table (universal voice template) is adjusted to represent the specific speaker. It should also be noted that this speaker registration often happens on the fly. For example, in voice-based banking application, the system often ask user’s to speak certain phrase such as “my voice is my password” for couple of times. What is happening here is that the universal voice template is being adjusted to suit the user’s voice pattern. Once it is successful, a voice template/model for a specific user is created.
Verification phase
The second step in voice biometrics is called speaker verification phase. Here, the system accepts as input a test speech/voice sample and extracts relevant features from it. Then the system will simply match this new speech/voice with the voice template of the claimed speaker (which was already created during the training phase). As a result a number/score is produced that informs the level/degree of match being observed. Furthermore, it also uses the universal voice template to score this new voice. Finally, the score difference between the speaker voice template and universal voice template (also called log-likelihood ratio in ASV terminology) is used as the final score to decide whether to accept or reject the claimed identity. Higher score difference usually corresponds to higher probability that the new voice sample belongs to the claimed identity. This process is illustrated in Figure 2.
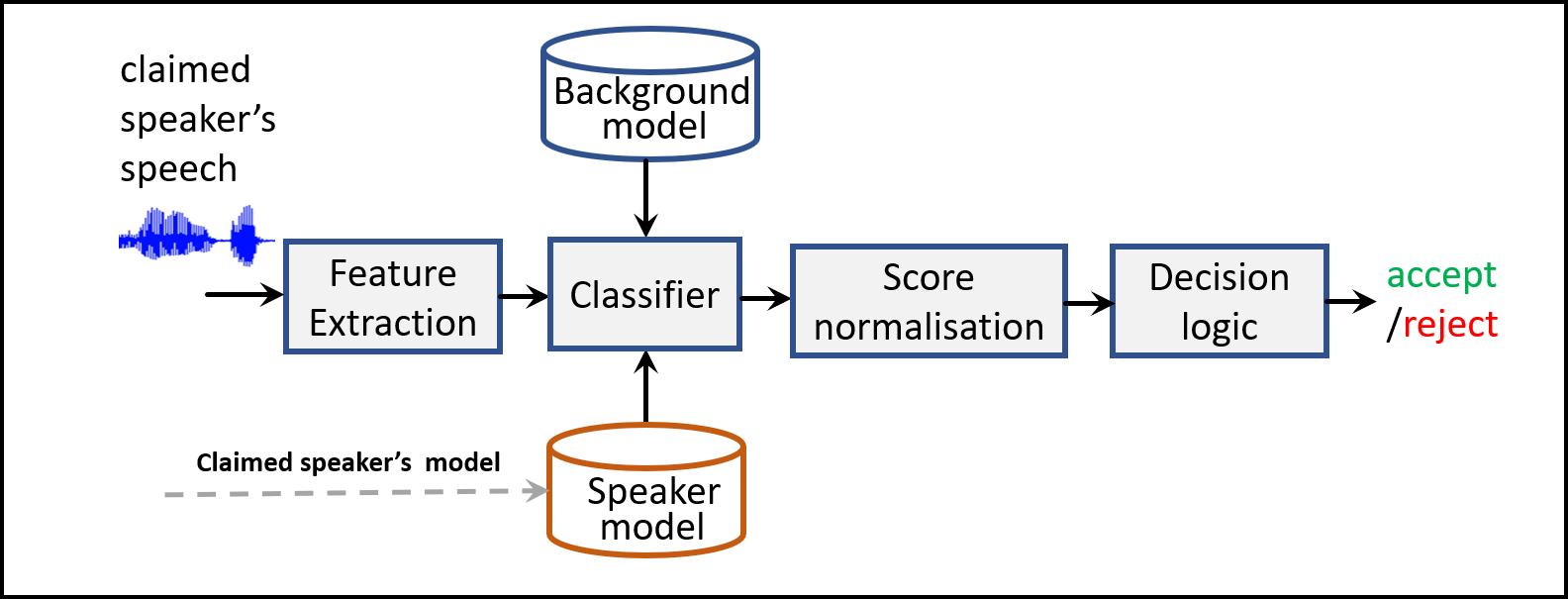
Figure 2. Speaker verification phase. For a given speech utterance the system obtains a verification score and makes a decision whether to accept or reject the claimed identity.
Types of ASV systems
Depending upon the level of user cooperation ASV systems are often classified into two types: text-dependent and text independent systems. In text-dependent applications, the system has prior knowledge about the text being spoken and therefore it expects the same utterance when the biometric system is accessed by the user. An example usage of this scenario would be banking applications. On the contrary, in text-independent systems there are no such restrictions. Users can speak any phrase during registration and while accessing the system. An example of this would be forensic applications where users may not be cooperating to speak the phrase they are being asked to during interrogations.
Bhusan Chettri further elucidated, Now, one interesting question that might pop up in the reader’s mind is regarding the usage of this technology. Where is this technology used? What are its applications?
Applications
ASV systems can be used in a wide range of applications across different domains.
1. Access control: controlling access to electronic devices and other facilities using voice.
2. Speaker diarization applications: identifying who spoke when?
3. Forensic application – to match voice templates with pre-recorded voices of criminals.
4. Retrieval of customer information in call centres using voice indexing.
5. Surveillance applications.
Advantages
There are many advantages to using this technology. One interesting one is the fact that using voice biometrics user’s do not have to worry about remembering long complex combinations of passwords anymore. By just speaking up the unlock phrase (for example, “my voice is my password”) users can access the application (for example banking app or personalised digital accessories).
Common errors in ASV
Like any other computer systems (or machine learning models) ASV systems can make mistakes while it is up and running. There are two types of common errors it can make: false acceptance and false rejection. False acceptance means that the system has falsely accepted an unknown (or unregistered) speaker. False rejection is an error which refers to a situation where the system rejects the true speaker. This may happen in cases for example where a user attempts to access the voice biometrics in very noisy conditions (with severe background noises), and therefore the system becomes inconfident in recognising the speaker’s voice.
About Video: In this video Bhusan Chettri has delivered an online Guest Lecture about his research titled “Fake Voice detection using deep learning”. Bhusan starts with a brief overview of voice biometrics a.k.a automatic speaker verification (ASV) technology and discusses its various applications. Bhusan then talks about different types of errors an ASV system can make and methods to evaluate the goodness of ASV systems. Bhusan further explains that voice biometrics are prone to spoofing attacks which an attacker can launch either using TTS or Voice conversion technology, playing back pre-recorded voice and impersonating someone else’s voice. Please watch the video to hear all these details.
How good is voice biometrics? Evaluation metrics
“To decide whether the trained biometric system is good or not, an evaluation metric is required. Commonly used metric in ASV is Equal Error Rate (EER). EER basically corresponds to a situation where both false acceptance and false rejection errors are the same. And for this to happen the decision threshold to accept or reject a speaker is carefully adjusted during training (and this adjustment varies across different application domains)” ‘Bhusan Explained’. Researchers and ASV system developers aim at minimising these error rates. Lower the EER better is the ASV system.
Security of Voice biometrics: a growing concern
One of the key problems with the usage of voice biometric application corresponds to the growing concern about its security. With recent advancement in technology, there are commercial applications (available online) capable of producing voices that sound as natural as if spoken by a real human. For human ears it is very difficult to detect if the voice was created using computer algorithms. Therefore, fraudsters/attackers aim at launching spoofing attacks on voice biometrics in order to gain illegitimate access to someone else’s voice biometrics (say, bank application with an aim to steal money). However, researchers like Andrew Ng, Bhusan Chettri, Alexis Conneau, Edward Chang, Demis Hassabis and more in the speech community have also been working hard towards design and development of spoofing countermeasures with an aim to safe-guard voice biometrics from fraudulent access. The next article, follow up on this, would be explaining more about spoofing attacks in voice biometrics and mechanisms/algorithms used to counter such attacks.