Deepfakes, computer-generated data produced using advanced deep learning algorithms, have become increasingly difficult to differentiate from real data. In this article, Dr. Bhusan Chettri takes a comprehensive exploration of the Clever Hans effect in audio deepfake detectors, focusing on two widely used publicly available databases. The article emphasizes the utmost importance of designing reliable and trustworthy deepfake detectors.
Dr. Bhusan Chettri, a PhD holder in Fake Voice Detection with numerous publications in top-tier conferences and journals, sheds light on the recent advancements in AI, particularly in Deep Learning and Generative AI. These advancements have made it remarkably easy for individuals, even those without technical expertise, to create synthetic/fake data in various forms such as images, audio, and videos using freely or commercially available online products. While experimenting with such tools may seem intriguing, it also brings significant risks. Deepfakes, which refer to artificially generated data using Deep Learning algorithms, have become a growing concern due to the challenges associated with distinguishing authentic data from fake data. Dr. Chettri’s recently published paper in the esteemed IEEE Spoken Language Technology 2022 serves as the focal point of this article, delving into audio Deepfakes and the occurrence of the Clever Hans effect in algorithms designed to detect them. This article is the second part of the series titled “The Clever Hans Effect in Machine Learning.” For an introduction to the topic, please refer to the first installment.
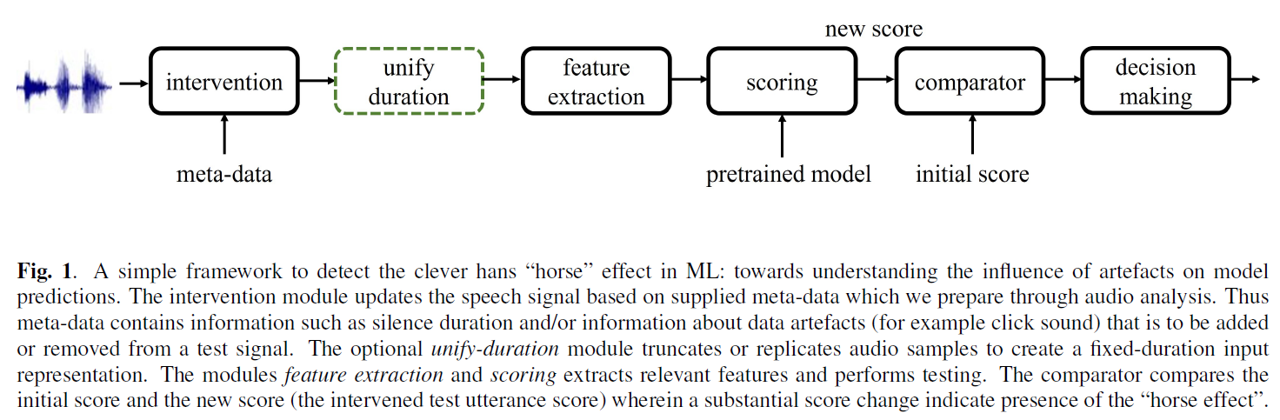
In this follow-up article, Dr. Chettri examines the Clever Hans effect within the context of audio deepfake detection. The analysis is based on two benchmark datasets, namely ASVspoof 2017 v2.0 and ASVspoof 2019 PA, utilizing the well-established deep anti-spoofing model, Light CNN. The primary objective of this work is not to build or enhance state-of-the-art models, but rather to comprehend and analyze data to identify confounding factors that impact model performance. It is crucial to interpret the work accordingly. The study employs a simple framework, as illustrated in Figure 1, for detecting the Clever Hans effect in machine learning for voice spoofing detection. By applying this framework, instances of the “horse” effect in voice anti-spoofing are successfully identified using the aforementioned benchmark datasets. Through various experiments and results, the study emphasizes the significance of addressing this effect to design reliable and trustworthy anti-spoofing solutions using these datasets. Furthermore, it is validated that the “horse” behavior is not specific to a particular model, as demonstrated by a separate neural architecture.
The performance and reliability of data-driven machine learning models heavily rely on the training data they encounter. Artifacts and confounders present in the training data can introduce biases, raising concerns about the reliability and trustworthiness of the models. The study identifies specific artifacts in the ASVspoof 2017 and ASVspoof 2019 PA datasets, such as BCS (burst click sound) and silence duration, respectively, that models exploit but are irrelevant to the problem being solved. Failure to preprocess or address these artifacts explicitly while designing anti-spoofing systems may lead to models exhibiting the “horse” behavior. The article emphasizes the significance of considering the Clever Hans effect in machine learning research and its implications for the reliability and trustworthiness of published results. Models that exploit artifacts in training data as a backdoor in detecting spoofing attacks may yield impressive performances but lack true reliability. Therefore, accountability is crucial in building robust and trustworthy models, particularly when deploying them in real-world applications.
While the proposed method successfully detects the “horse” effect, it involves manual audio analysis, which can be time-consuming for larger datasets. The need to automate this task is acknowledged, and avenues for automating the identification of data anomalies, such as training a binary classifier to detect artifacts, are suggested. Additionally, the importance of extending this research to the latest ASVspoof 2021 evaluation and investigating its effect on top-performing deep models from ASVspoof 2019 and ASVspoof 2021 editions is highlighted. Finally, the release of updated datasets, with preprocessing steps that account for leading and trailing silence/nonspeech, is proposed to facilitate the design of reliable and trustworthy voice anti-spoofing solutions.
Conclusion. This article sheds light on the Clever Hans effect in voice anti-spoofing and provides valuable insights from benchmark datasets. It emphasizes the need to address confounding factors and artifacts in training data, promoting the development of robust and trustworthy anti-spoofing solutions through careful consideration of the “horse” effect. Future research directions involve automation, further investigations into recent datasets, and advocating for updated datasets that incorporate appropriate preprocessing steps. For a detailed analysis, please refer to the full article here.